

{kind=link}
- NVIDIA Blackwell swept the brand new SemiAnalysis InferenceMAX v1 benchmarks, delivering the best efficiency and greatest total effectivity.
- InferenceMax v1 is the primary impartial benchmark to measure complete price of compute throughout numerous fashions and real-world eventualities.
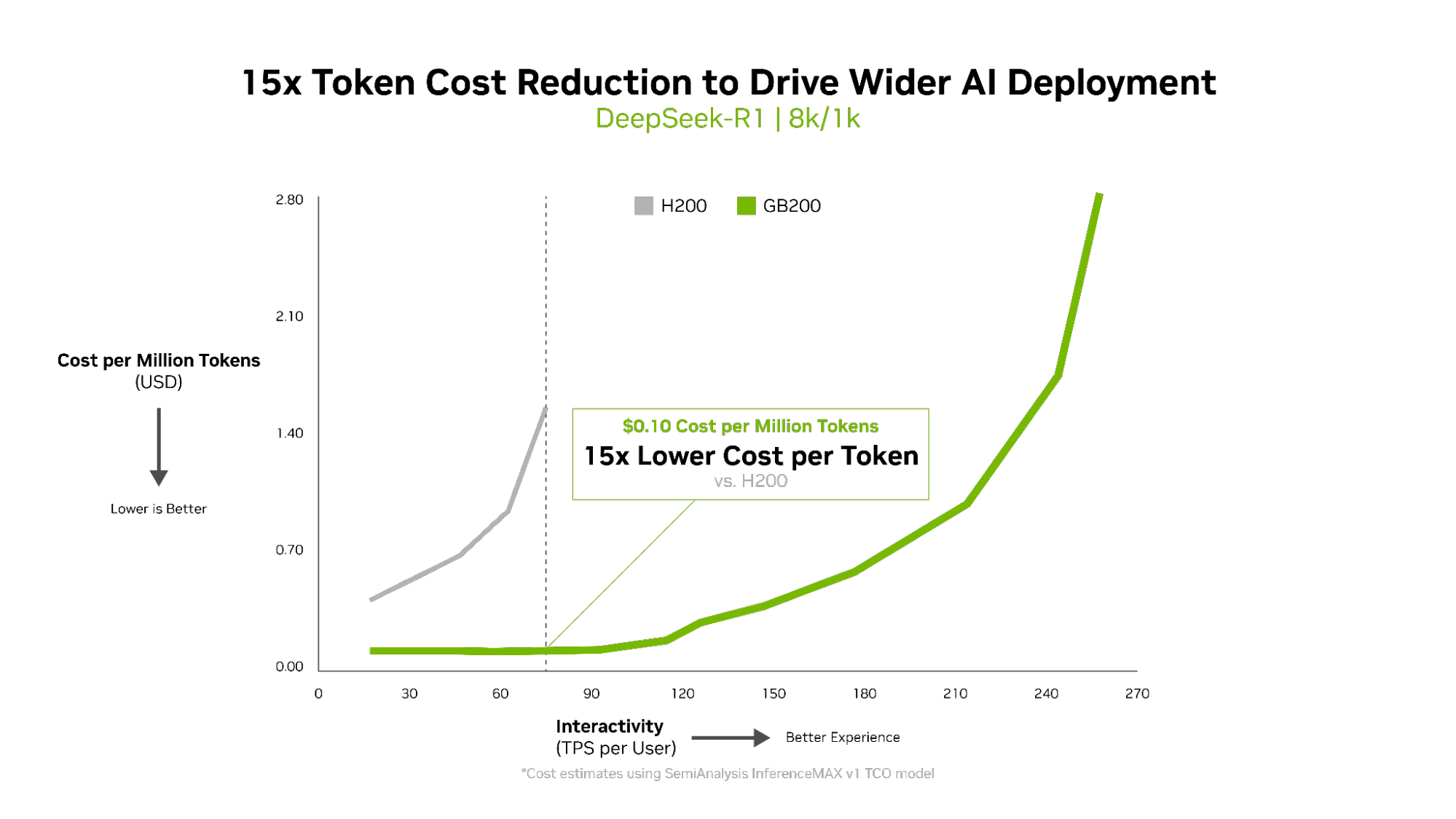
- Greatest return on funding: NVIDIA GB200 NVL72 delivers unmatched AI manufacturing unit economics — a $5 million funding generates $75 million in DSR1 token income, a 15x return on funding.
- Lowest complete price of possession: NVIDIA B200 software program optimizations obtain two cents per million tokens on gpt-oss, delivering 5x decrease price per token in simply 2 months.
- Greatest throughput and interactivity: NVIDIA B200 units the tempo with 60,000 tokens per second per GPU and 1,000 tokens per second per person on gpt-oss with the most recent NVIDIA TensorRT-LLM stack.
As AI shifts from one-shot solutions to advanced reasoning, the demand for inference — and the economics behind it — is exploding.
The brand new impartial InferenceMAX v1 benchmarks are the primary to measure complete price of compute throughout real-world eventualities. The outcomes? The NVIDIA Blackwell platform swept the sector — delivering unmatched efficiency and greatest total effectivity for AI factories.
A $5 million funding in an NVIDIA GB200 NVL72 system can generate $75 million in token income. That’s a 15x return on funding (ROI) — the brand new economics of inference.
“Inference is the place AI delivers worth day by day,” mentioned Ian Buck, vp of hyperscale and high-performance computing at NVIDIA. “These outcomes present that NVIDIA’s full-stack method provides clients the efficiency and effectivity they should deploy AI at scale.”
Enter InferenceMAX v1
InferenceMAX v1, a brand new benchmark from SemiAnalysis launched Monday, is the most recent to spotlight Blackwell’s inference management. It runs well-liked fashions throughout main platforms, measures efficiency for a variety of use circumstances and publishes outcomes anybody can confirm.
Why do benchmarks like this matter?
As a result of trendy AI isn’t nearly uncooked pace — it’s about effectivity and economics at scale. As fashions shift from one-shot replies to multistep reasoning and power use, they generate much more tokens per question, dramatically growing compute calls for.
NVIDIA’s open-source collaborations with OpenAI (gpt-oss 120B), Meta (Llama 3 70B), and DeepSeek AI (DeepSeek R1) spotlight how community-driven fashions are advancing state-of-the-art reasoning and effectivity.
Partnering with these main mannequin builders and the open-source neighborhood, NVIDIA ensures the most recent fashions are optimized for the world’s largest AI inference infrastructure. These efforts replicate a broader dedication to open ecosystems — the place shared innovation accelerates progress for everybody.
Deep collaborations with the FlashInfer, SGLang and vLLM communities allow codeveloped kernel and runtime enhancements that energy these fashions at scale.
Software program Optimizations Ship Continued Efficiency Features
NVIDIA repeatedly improves efficiency via {hardware} and software program codesign optimizations. Preliminary gpt-oss-120b efficiency on an NVIDIA DGX Blackwell B200 system with the NVIDIA TensorRT LLM library was market-leading, however NVIDIA’s groups and the neighborhood have considerably optimized TensorRT LLM for open-source massive language fashions.
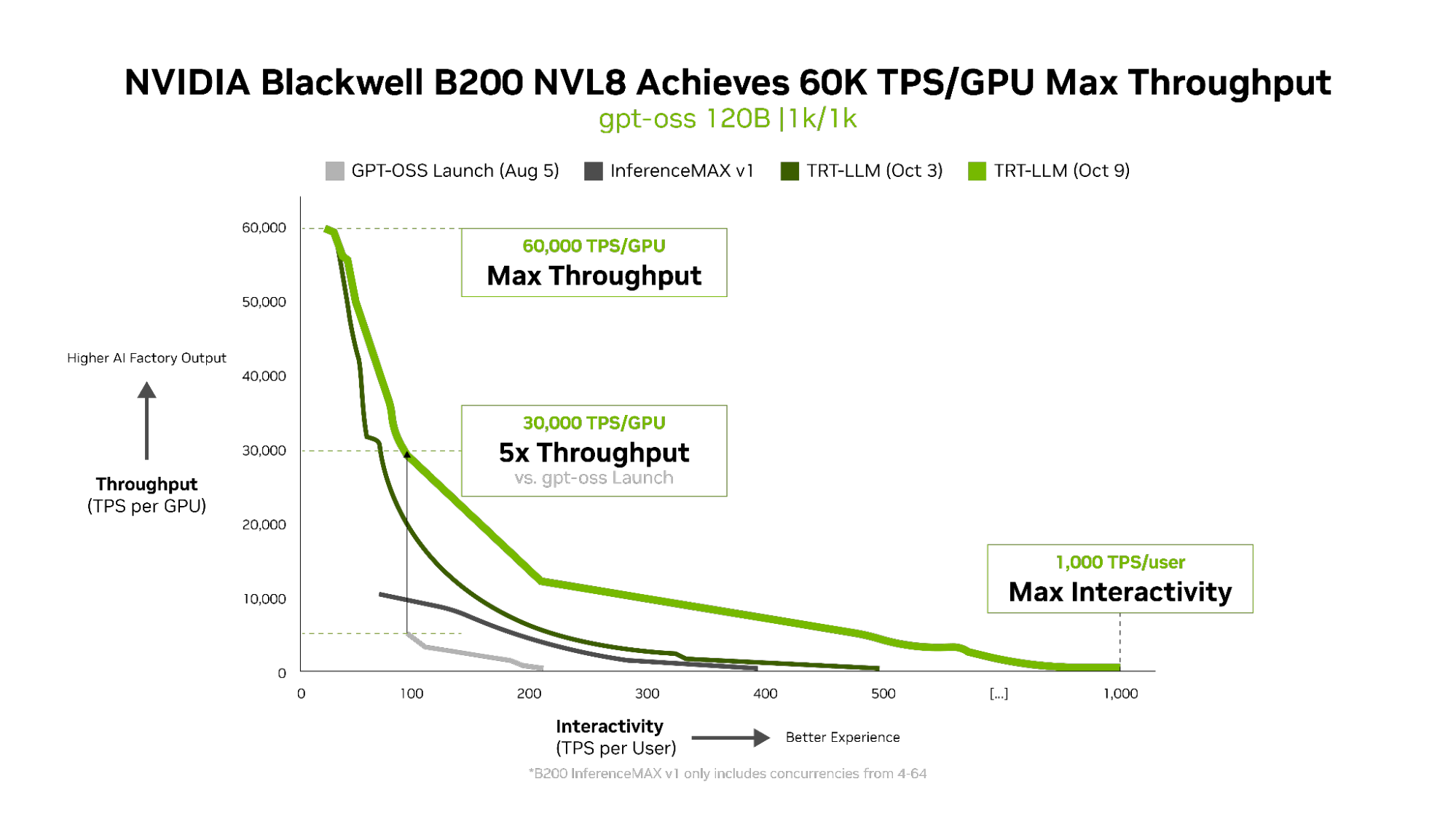
The TensorRT LLM v1.0 launch is a significant breakthrough in making massive AI fashions sooner and extra responsive for everybody.
By way of superior parallelization methods, it makes use of the B200 system and NVIDIA NVLink Swap’s 1,800 GB/s bidirectional bandwidth to dramatically enhance the efficiency of the gpt-oss-120b mannequin.
The innovation doesn’t cease there. The newly launched gpt-oss-120b-Eagle3-v2 mannequin introduces speculative decoding, a intelligent methodology that predicts a number of tokens at a time.
This reduces lag and delivers even faster outcomes, tripling throughput at 100 tokens per second per person (TPS/person) — boosting per-GPU speeds from 6,000 to 30,000 tokens.
For dense AI fashions like Llama 3.3 70B, which demand important computational sources resulting from their massive parameter rely and the truth that all parameters are utilized concurrently throughout inference, NVIDIA Blackwell B200 units a brand new efficiency commonplace in InferenceMAX v1 benchmarks.
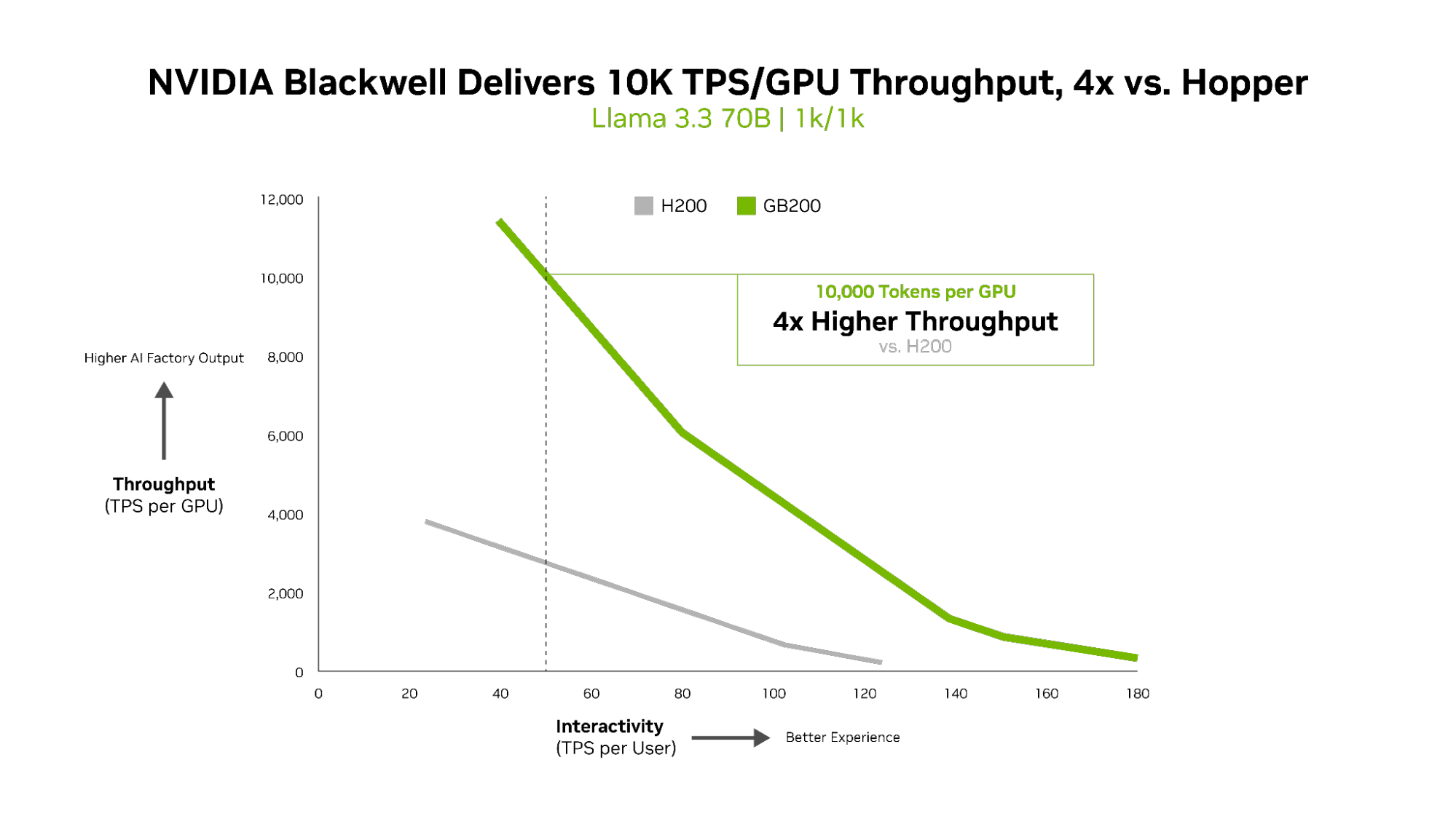
Blackwell delivers over 10,000 TPS per GPU at 50 TPS per person interactivity — 4x increased per-GPU throughput in contrast with the NVIDIA H200 GPU.
Efficiency Effectivity Drives Worth
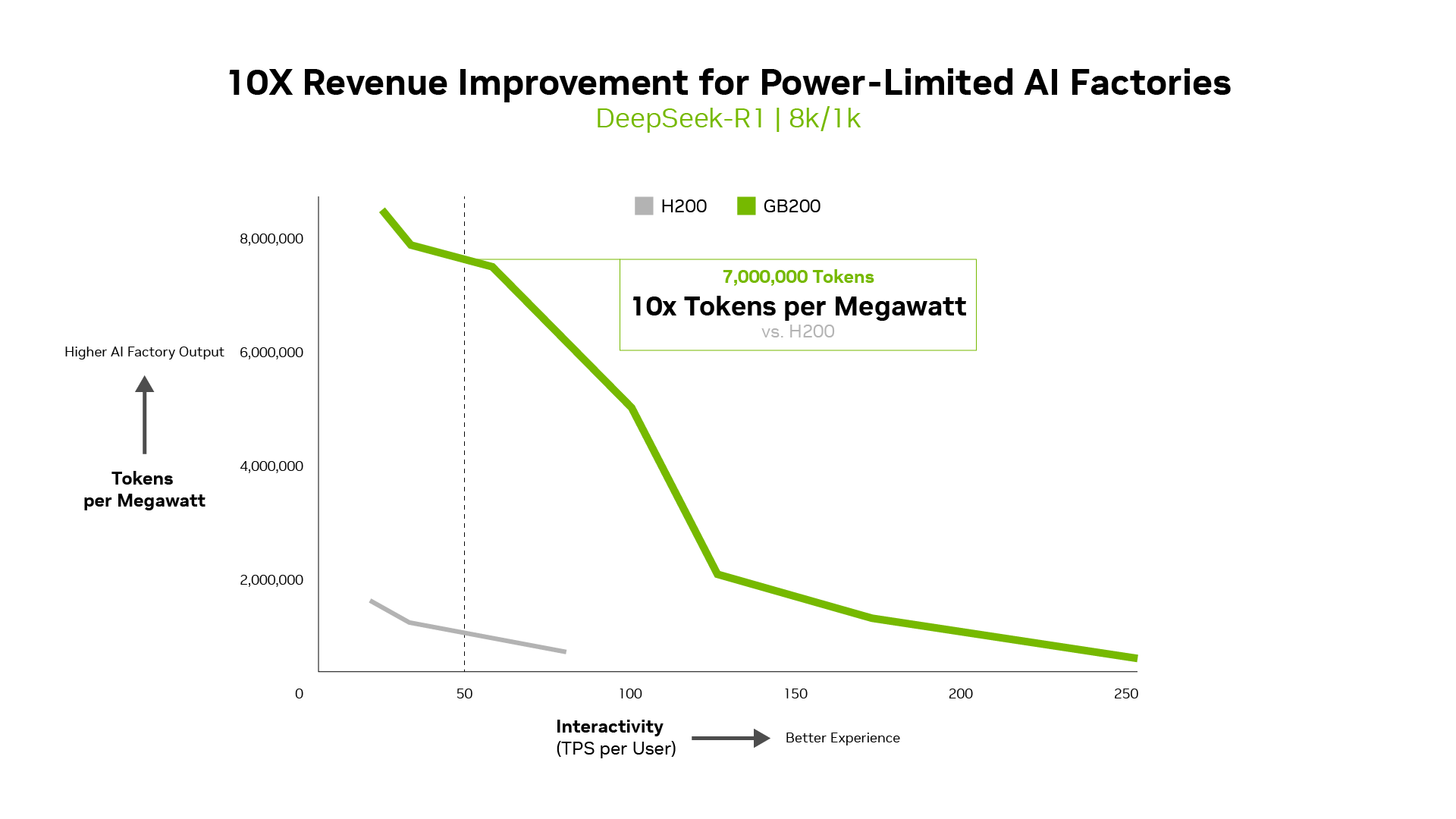
Metrics like tokens per watt, price per million tokens and TPS/person matter as a lot as throughput. Actually, for power-limited AI factories, Blackwell delivers 10x throughput per megawatt in contrast with the earlier era, which interprets into increased token income.
The associated fee per token is essential for evaluating AI mannequin effectivity, instantly impacting operational bills. The NVIDIA Blackwell structure lowered price per million tokens by 15x versus the earlier era, resulting in substantial financial savings and fostering wider AI deployment and innovation.
Multidimensional Efficiency
InferenceMAX makes use of the Pareto frontier — a curve that exhibits the perfect trade-offs between various factors, corresponding to information heart throughput and responsiveness — to map efficiency.
But it surely’s greater than a chart. It displays how NVIDIA Blackwell balances the complete spectrum of manufacturing priorities: price, vitality effectivity, throughput and responsiveness. That stability permits the best ROI throughout real-world workloads.
Techniques that optimize for only one mode or situation could present peak efficiency in isolation, however the economics of that doesn’t scale. Blackwell’s full-stack design delivers effectivity and worth the place it issues most: in manufacturing.
For a deeper take a look at how these curves are constructed — and why they matter for complete price of possession and service-level settlement planning — try this technical deep dive for full charts and methodology.
What Makes It Doable?
Blackwell’s management comes from excessive hardware-software codesign. It’s a full-stack structure constructed for pace, effectivity and scale:
- The Blackwell structure options embody:
- NVFP4 low-precision format for effectivity with out lack of accuracy
- Fifth-generation NVIDIA NVLink that connects 72 Blackwell GPUs to behave as one big GPU
- NVLink Swap, which permits excessive concurrency via superior tensor, professional and information parallel consideration algorithms
- Annual {hardware} cadence plus steady software program optimization — NVIDIA has greater than doubled Blackwell efficiency since launch utilizing software program alone
- NVIDIA TensorRT-LLM, NVIDIA Dynamo, SGLang and vLLM open-source inference frameworks optimized for peak efficiency
- A large ecosystem, with lots of of tens of millions of GPUs put in, 7 million CUDA builders and contributions to over 1,000 open-source tasks
The Greater Image
AI is transferring from pilots to AI factories — infrastructure that manufactures intelligence by turning information into tokens and selections in actual time.
Open, regularly up to date benchmarks assist groups make knowledgeable platform decisions, tune for price per token, latency service-level agreements and utilization throughout altering workloads.
NVIDIA’s Assume SMART framework helps enterprises navigate this shift, spotlighting how NVIDIA’s full-stack inference platform delivers real-world ROI — turning efficiency into income.